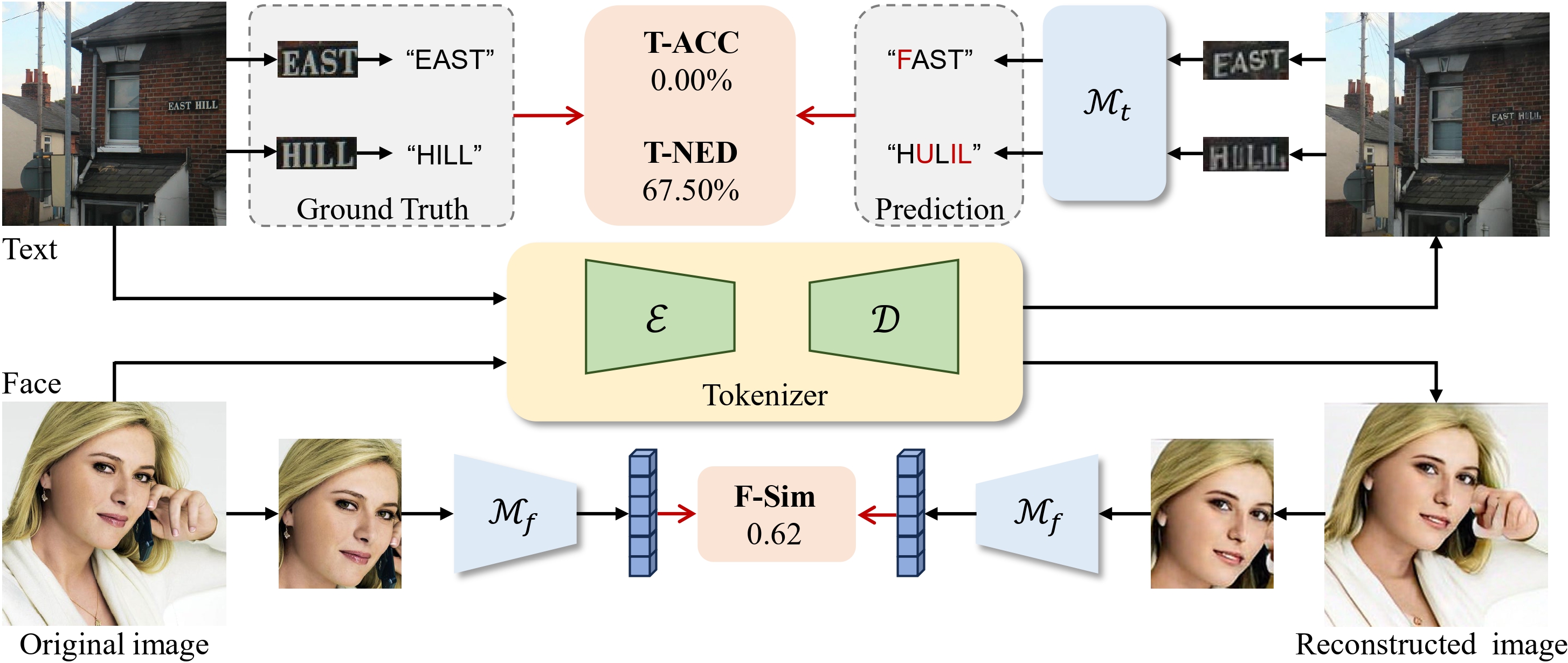
Feel free to email us, we'd be happy to assist in incorporating your Tokenizer or VAE results into our leaderboard.
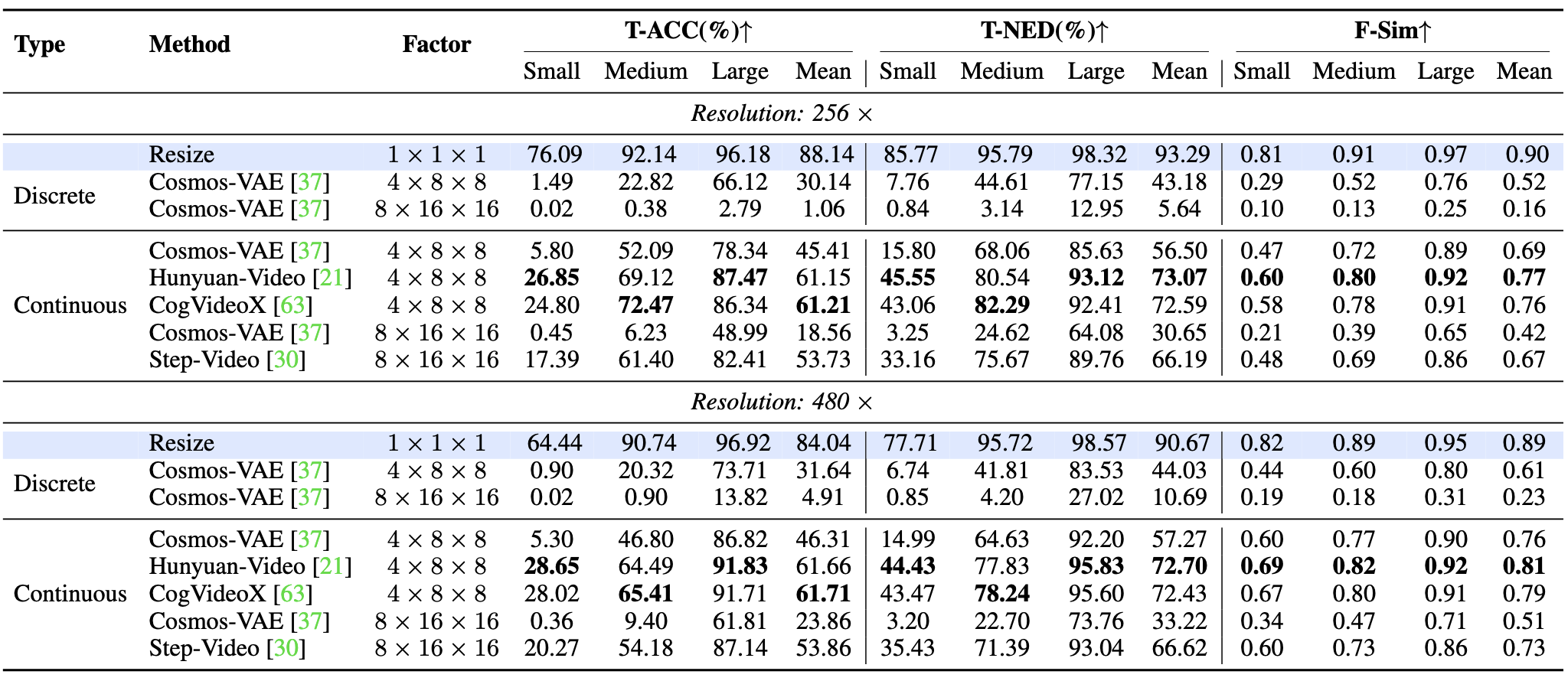
| # | Method | Type | Factor | T-ACC↑ | T-NED↑ | F-Sim↑ | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task Split | Small | Medium | Large | Mean | Small | Medium | Large | Mean | Small | Medium | Large | Mean | |||||
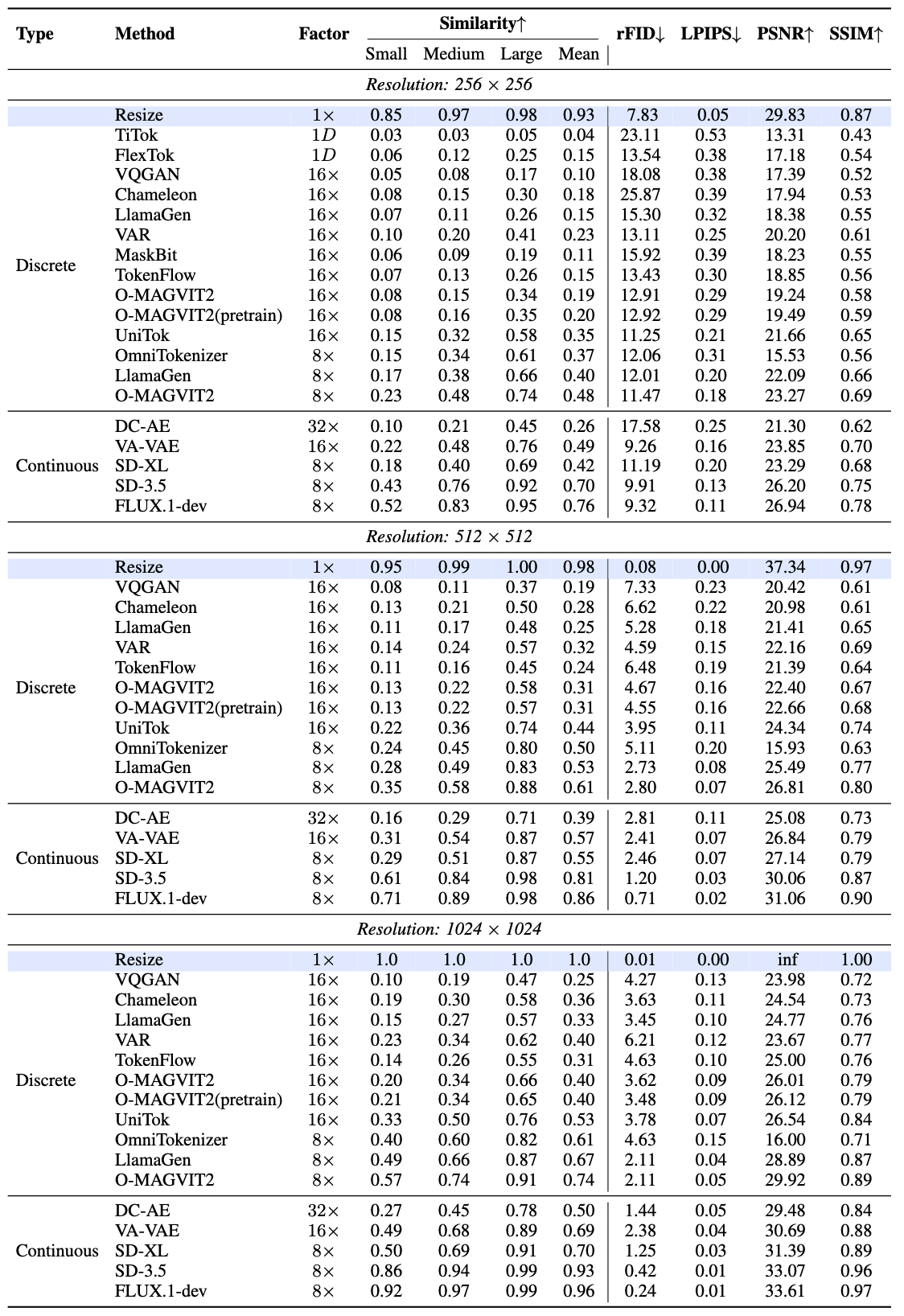
| Resolution: 256 × 256 | |||||||||||||||||
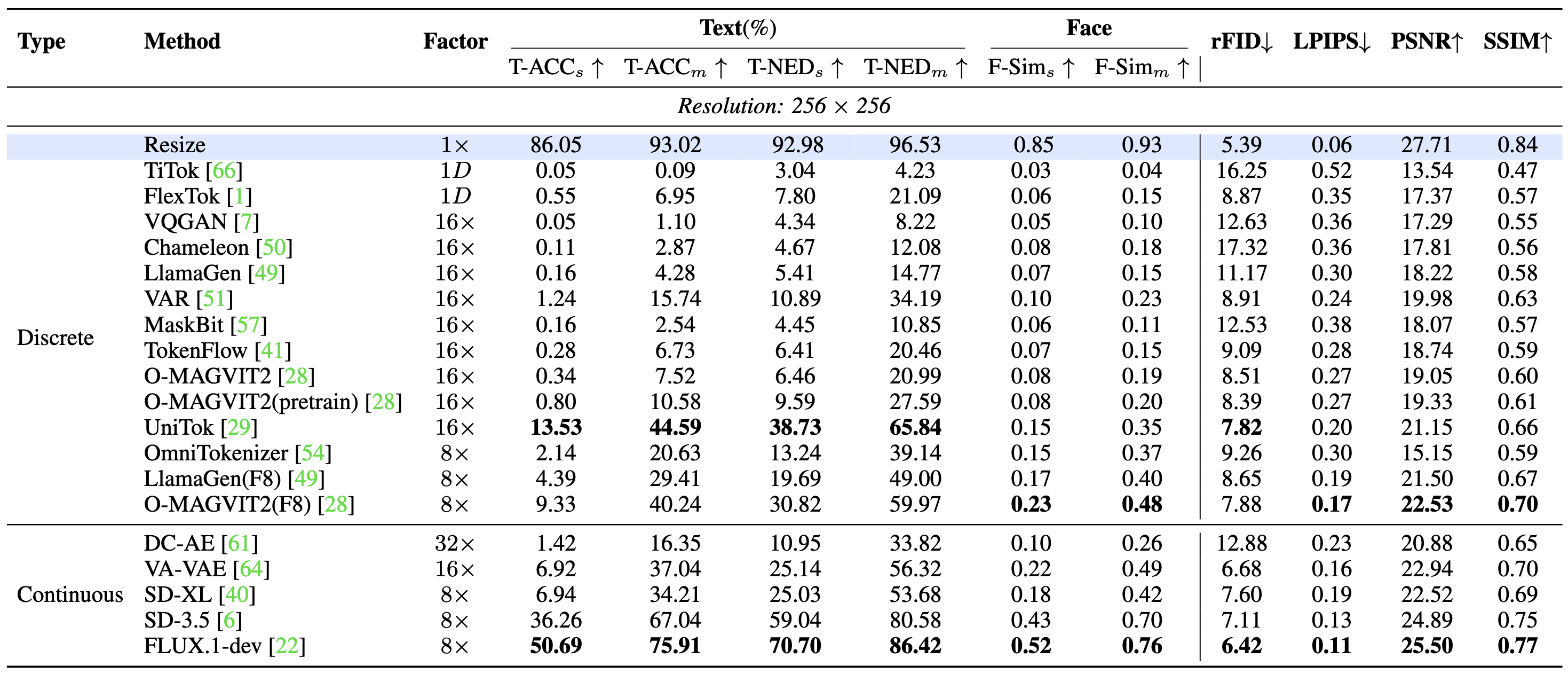
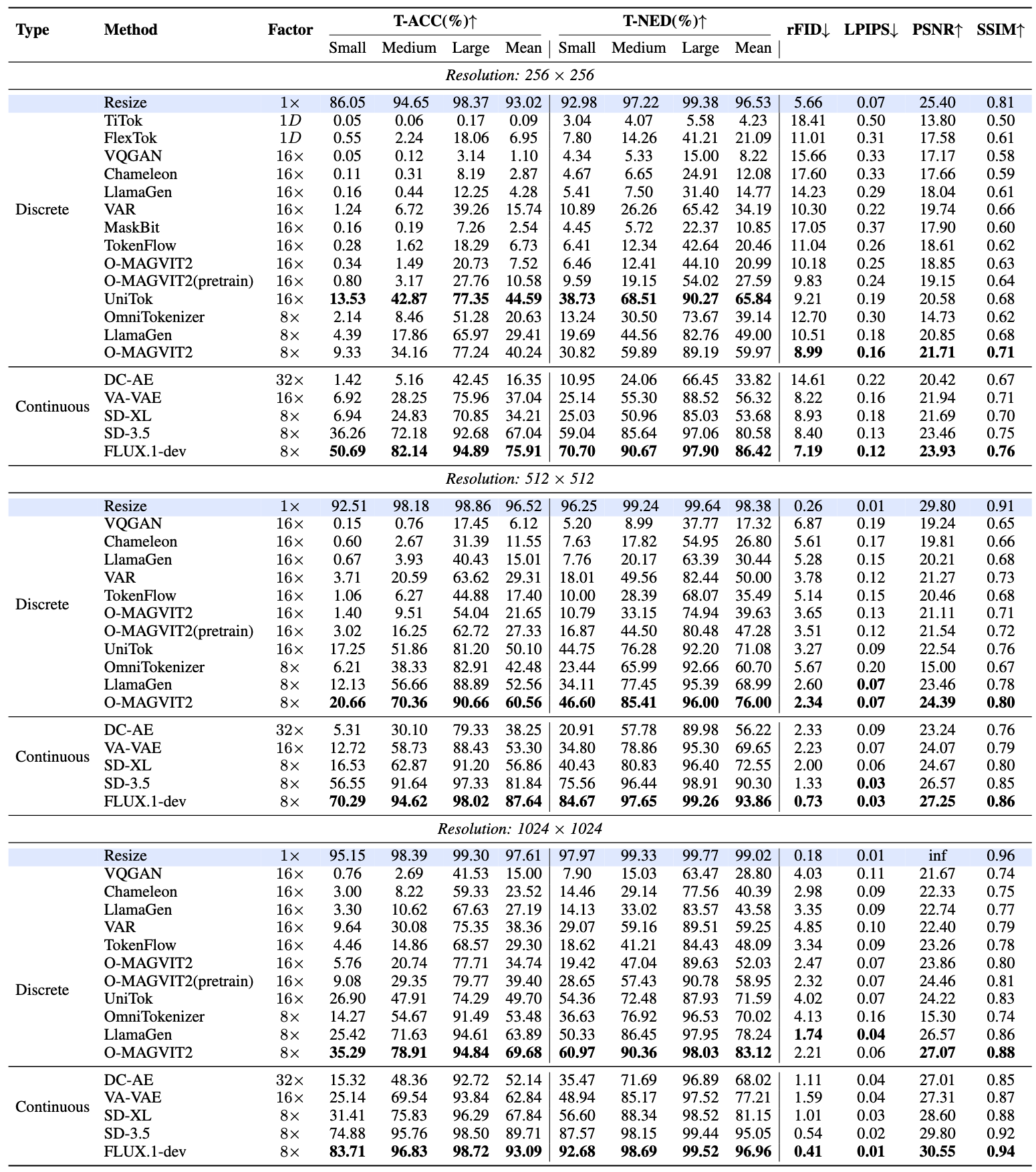
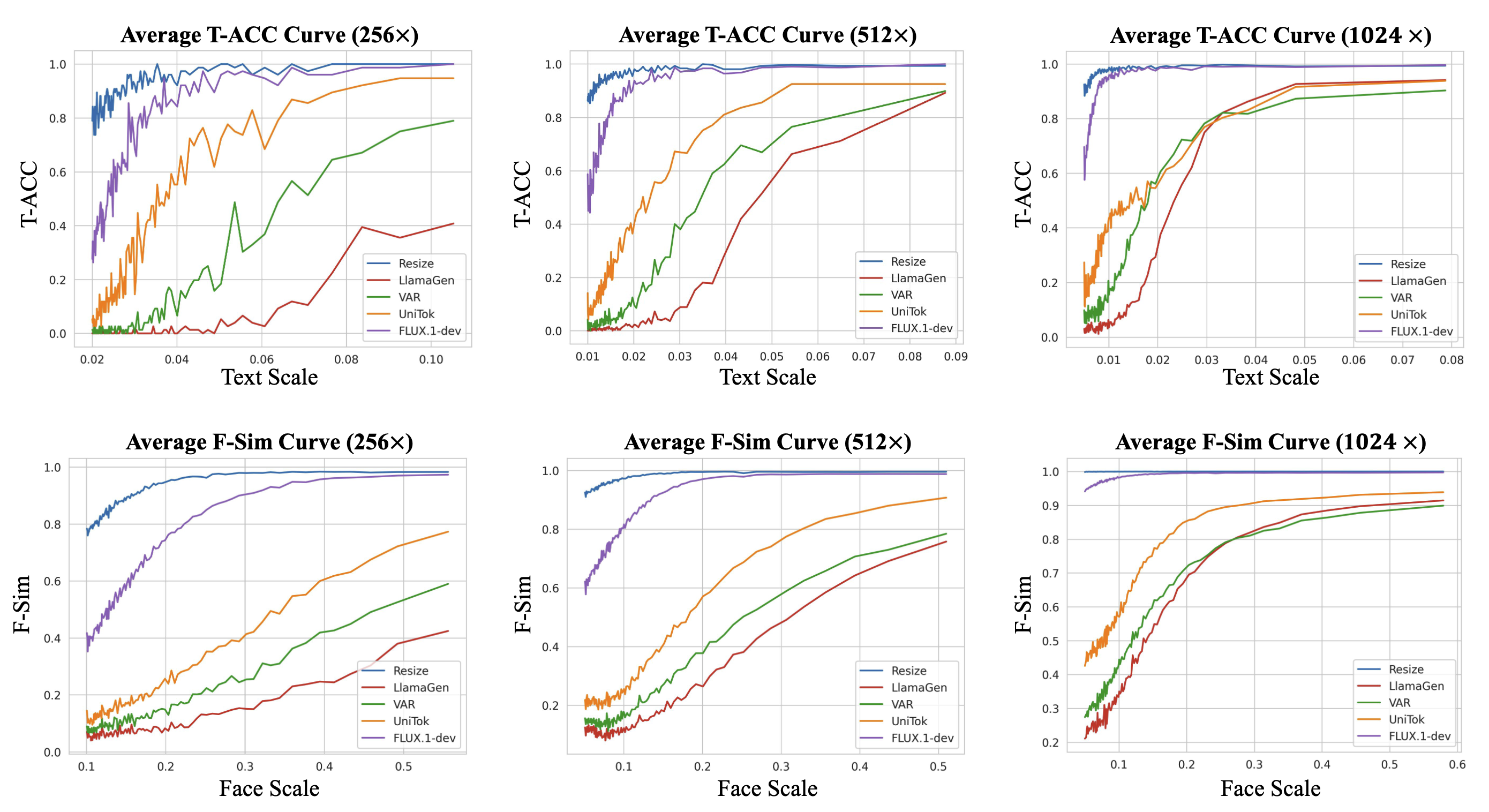
| Resize | - | - | 86.05 | 94.65 | 98.37 | 93.02 | 92.98 | 97.22 | 99.38 | 96.53 | 0.85 | 0.97 | 0.98 | 0.93 | |||
| TiTok | Discrete | 1D | 0.05 | 0.06 | 0.17 | 0.09 | 3.04 | 4.07 | 5.58 | 4.23 | 0.03 | 0.03 | 0.05 | 0.04 | |||
| FlexTok | Discrete | 1D | 0.55 | 2.24 | 18.06 | 6.95 | 7.80 | 14.26 | 41.21 | 21.09 | 0.06 | 0.12 | 0.25 | 0.15 | |||
| VQGAN | Discrete | 16× | 0.05 | 0.12 | 3.14 | 1.10 | 4.34 | 5.33 | 15.00 | 8.22 | 0.05 | 0.08 | 0.17 | 0.10 | |||
| Chameleon | Discrete | 16× | 0.11 | 0.31 | 8.19 | 2.87 | 4.67 | 6.65 | 24.91 | 12.08 | 0.08 | 0.15 | 0.30 | 0.18 | |||
| LlamaGen | Discrete | 16× | 0.16 | 0.44 | 12.25 | 4.28 | 5.41 | 7.50 | 31.40 | 14.77 | 0.07 | 0.11 | 0.26 | 0.15 | |||
| VAR | Discrete | 16× | 1.24 | 6.72 | 39.26 | 15.74 | 10.89 | 26.26 | 65.42 | 34.19 | 0.10 | 0.20 | 0.41 | 0.23 | |||
| MaskBit | Discrete | 16× | 0.16 | 0.19 | 7.26 | 2.54 | 4.45 | 5.72 | 22.37 | 10.85 | 0.06 | 0.09 | 0.19 | 0.11 | |||
| TokenFlow | Discrete | 16× | 0.28 | 1.62 | 18.29 | 6.73 | 6.41 | 12.34 | 42.64 | 20.46 | 0.07 | 0.13 | 0.26 | 0.15 | |||
| O-MAGVIT2 | Discrete | 16× | 0.34 | 1.49 | 20.73 | 7.52 | 6.46 | 12.41 | 44.10 | 20.99 | 0.08 | 0.15 | 0.34 | 0.19 | |||
| O-MAGVIT2(Pretrain) | Discrete | 16× | 0.80 | 3.17 | 27.76 | 10.58 | 9.59 | 19.15 | 54.02 | 27.59 | 0.08 | 0.16 | 0.35 | 0.20 | |||
| MGVQ-g8 | Discrete | 16× | 11.08 | 37.71 | 80.66 | 43.15 | 32.80 | 63.16 | 90.92 | 62.29 | 0.22 | 0.47 | 0.74 | 0.47 | |||
| UniTok | Discrete | 16× | 13.53 | 42.87 | 77.35 | 44.59 | 38.73 | 68.51 | 90.27 | 65.84 | 0.15 | 0.32 | 0.58 | 0.35 | |||
| OmniTokenizer | Discrete | 8× | 2.14 | 8.46 | 51.28 | 20.63 | 13.24 | 30.50 | 73.67 | 39.14 | 0.15 | 0.34 | 0.61 | 0.37 | |||
| LlamaGen(F8) | Discrete | 8× | 4.39 | 17.86 | 65.97 | 29.41 | 19.69 | 44.56 | 82.76 | 49.00 | 0.17 | 0.38 | 0.66 | 0.40 | |||
| O-MAGVIT2(F8) | Discrete | 8× | 9.33 | 34.16 | 77.24 | 40.24 | 30.82 | 59.89 | 89.19 | 59.97 | 0.23 | 0.48 | 0.74 | 0.48 | |||
| MGVQ-g8 | Discrete | 8× | 63.83 | 88.05 | 96.05 | 82.65 | 80.18 | 94.15 | 98.54 | 90.96 | 0.58 | 0.86 | 0.95 | 0.80 | |||
| DC-AE | Continuous | 32× | 1.42 | 5.16 | 42.45 | 16.35 | 10.95 | 24.06 | 66.45 | 33.82 | 0.10 | 0.21 | 0.45 | 0.26 | |||
| VA-VAE | Continuous | 16× | 6.92 | 28.25 | 75.96 | 37.04 | 25.14 | 55.30 | 88.52 | 56.32 | 0.22 | 0.48 | 0.76 | 0.49 | |||
| SD-XL | Continuous | 8× | 6.94 | 24.83 | 70.85 | 34.21 | 25.03 | 50.96 | 85.03 | 53.68 | 0.18 | 0.40 | 0.69 | 0.42 | |||
| SD-3.5 | Continuous | 8× | 36.26 | 72.18 | 92.68 | 67.04 | 59.04 | 85.64 | 97.06 | 80.58 | 0.43 | 0.76 | 0.92 | 0.70 | |||
| FLUX.1-dev | Continuous | 8× | 50.69 | 82.14 | 94.89 | 75.91 | 70.70 | 90.67 | 97.90 | 86.42 | 0.52 | 0.83 | 0.95 | 0.76 | |||
| Resolution: 512 × 512 | |||||||||||||||||
| Resize | - | - | 92.51 | 98.18 | 98.86 | 96.52 | 96.25 | 99.24 | 99.64 | 98.38 | 0.95 | 0.99 | 1.00 | 0.98 | |||
| VQGAN | Discrete | 16× | 0.15 | 0.76 | 17.45 | 6.12 | 5.20 | 8.99 | 37.77 | 17.32 | 0.08 | 0.11 | 0.37 | 0.19 | |||
| Chameleon | Discrete | 16× | 0.60 | 2.67 | 31.39 | 11.55 | 7.63 | 17.82 | 54.95 | 26.80 | 0.13 | 0.21 | 0.50 | 0.28 | |||
| LlamaGen | Discrete | 16× | 0.67 | 3.93 | 40.43 | 15.01 | 7.76 | 20.17 | 63.39 | 30.44 | 0.11 | 0.17 | 0.48 | 0.25 | |||
| VAR | Discrete | 16× | 3.71 | 20.59 | 63.62 | 29.31 | 18.01 | 49.56 | 82.44 | 50.00 | 0.14 | 0.24 | 0.57 | 0.32 | |||
| TokenFlow | Discrete | 16× | 1.06 | 6.27 | 44.88 | 17.40 | 10.00 | 28.39 | 68.07 | 35.49 | 0.11 | 0.16 | 0.45 | 0.24 | |||
| O-MAGVIT2 | Discrete | 16× | 1.40 | 9.51 | 54.04 | 21.65 | 10.79 | 33.15 | 74.94 | 39.63 | 0.13 | 0.22 | 0.58 | 0.31 | |||
| O-MAGVIT2(Pretrain) | Discrete | 16× | 3.02 | 16.25 | 62.72 | 27.33 | 16.87 | 44.50 | 80.48 | 47.28 | 0.13 | 0.22 | 0.57 | 0.31 | |||
| MGVQ-g8 | Discrete | 16× | 23.67 | 76.38 | 94.35 | 64.80 | 49.32 | 88.73 | 97.73 | 78.60 | 0.34 | 0.58 | 0.90 | 0.61 | |||
| UniTok | Discrete | 16× | 17.25 | 51.86 | 81.20 | 50.10 | 44.75 | 76.28 | 92.20 | 71.08 | 0.22 | 0.36 | 0.74 | 0.44 | |||
| OmniTokenizer | Discrete | 8× | 6.21 | 38.33 | 82.91 | 42.48 | 23.44 | 65.99 | 92.66 | 60.70 | 0.24 | 0.45 | 0.80 | 0.50 | |||
| LlamaGen(F8) | Discrete | 8× | 12.13 | 56.66 | 88.89 | 52.56 | 34.11 | 77.45 | 95.39 | 68.99 | 0.28 | 0.49 | 0.83 | 0.53 | |||
| O-MAGVIT2(F8) | Discrete | 8× | 20.66 | 70.36 | 90.66 | 60.56 | 46.60 | 85.41 | 96.00 | 76.00 | 0.35 | 0.58 | 0.88 | 0.61 | |||
| MGVQ-g8 | Discrete | 8× | 78.48 | 95.84 | 97.72 | 90.68 | 89.17 | 98.21 | 99.17 | 95.52 | 0.76 | 0.91 | 0.98 | 0.89 | |||
| DC-AE | Continuous | 32× | 5.31 | 30.10 | 79.33 | 38.25 | 20.91 | 57.78 | 89.98 | 56.22 | 0.16 | 0.29 | 0.71 | 0.39 | |||
| VA-VAE | Continuous | 16× | 12.72 | 58.73 | 88.43 | 53.30 | 34.80 | 78.86 | 95.30 | 69.65 | 0.31 | 0.54 | 0.87 | 0.57 | |||
| SD-XL | Continuous | 8× | 16.53 | 62.87 | 91.20 | 56.86 | 40.43 | 80.83 | 96.40 | 72.55 | 0.29 | 0.51 | 0.87 | 0.55 | |||
| SD-3.5 | Continuous | 8× | 56.55 | 91.64 | 97.33 | 81.84 | 75.56 | 96.44 | 98.91 | 90.30 | 0.61 | 0.84 | 0.98 | 0.81 | |||
| FLUX.1-dev | Continuous | 8× | 70.29 | 94.62 | 98.02 | 87.64 | 84.67 | 97.65 | 99.26 | 93.86 | 0.71 | 0.89 | 0.98 | 0.86 | |||
| Resolution: 1024 × 1024 | |||||||||||||||||
| Resize | - | - | 95.15 | 98.39 | 99.30 | 97.61 | 97.97 | 99.33 | 99.77 | 99.02 | 1.0 | 1.0 | 1.0 | 1.0 | |||
| VQGAN | Discrete | 16× | 0.76 | 2.69 | 41.53 | 15.00 | 7.90 | 15.03 | 63.47 | 28.80 | 0.10 | 0.19 | 0.47 | 0.25 | |||
| Chameleon | Discrete | 16× | 3.00 | 8.22 | 59.33 | 23.52 | 14.46 | 29.14 | 77.56 | 40.39 | 0.19 | 0.30 | 0.58 | 0.36 | |||
| LlamaGen | Discrete | 16× | 3.30 | 10.62 | 67.63 | 27.19 | 14.13 | 33.02 | 83.57 | 43.58 | 0.15 | 0.27 | 0.57 | 0.33 | |||
| VAR | Discrete | 16× | 9.64 | 30.08 | 75.35 | 38.36 | 29.07 | 59.16 | 89.51 | 59.25 | 0.23 | 0.34 | 0.62 | 0.40 | |||
| TokenFlow | Discrete | 16× | 4.46 | 14.86 | 68.57 | 29.30 | 18.62 | 41.21 | 84.43 | 48.09 | 0.14 | 0.26 | 0.55 | 0.31 | |||
| O-MAGVIT2 | Discrete | 16× | 5.76 | 20.74 | 77.71 | 34.74 | 19.42 | 47.04 | 89.63 | 52.03 | 0.20 | 0.34 | 0.66 | 0.40 | |||
| O-MAGVIT2(Pretrain) | Discrete | 16× | 9.08 | 29.35 | 79.77 | 39.40 | 28.65 | 57.43 | 90.78 | 58.95 | 0.21 | 0.34 | 0.65 | 0.40 | |||
| MGVQ-g8 | Discrete | 16× | 40.77 | 84.75 | 96.76 | 74.09 | 65.26 | 93.00 | 98.75 | 85.67 | 0.92 | 0.97 | 0.99 | 0.96 | |||
| UniTok | Discrete | 16× | 26.90 | 47.91 | 74.29 | 49.70 | 54.36 | 72.48 | 87.93 | 71.59 | 0.33 | 0.50 | 0.76 | 0.53 | |||
| OmniTokenizer | Discrete | 8× | 14.27 | 54.67 | 91.49 | 53.48 | 36.63 | 76.92 | 96.53 | 70.02 | 0.40 | 0.60 | 0.82 | 0.61 | |||
| LlamaGen(F8) | Discrete | 8× | 25.42 | 71.63 | 94.61 | 63.89 | 50.33 | 86.45 | 97.95 | 78.24 | 0.49 | 0.66 | 0.87 | 0.67 | |||
| O-MAGVIT2(F8) | Discrete | 8× | 35.29 | 78.91 | 94.84 | 69.68 | 60.97 | 90.36 | 98.03 | 83.12 | 0.57 | 0.74 | 0.91 | 0.74 | |||
| MGVQ-g8 | Discrete | 8× | 87.58 | 96.96 | 98.59 | 94.38 | 94.58 | 98.74 | 99.47 | 97.60 | 0.92 | 0.97 | 0.99 | 0.96 | |||
| DC-AE | Continuous | 32× | 15.32 | 48.36 | 92.72 | 52.14 | 35.47 | 71.69 | 96.89 | 68.02 | 0.27 | 0.45 | 0.78 | 0.50 | |||
| VA-VAE | Continuous | 16× | 25.14 | 69.54 | 93.84 | 62.84 | 48.94 | 85.17 | 97.52 | 77.21 | 0.49 | 0.68 | 0.89 | 0.69 | |||
| SD-XL | Continuous | 8× | 31.41 | 75.83 | 96.29 | 67.84 | 56.60 | 88.34 | 98.52 | 81.15 | 0.50 | 0.69 | 0.91 | 0.70 | |||
| SD-3.5 | Continuous | 8× | 74.88 | 95.76 | 98.50 | 89.71 | 87.57 | 98.15 | 99.44 | 95.05 | 0.86 | 0.94 | 0.99 | 0.93 | |||
| FLUX.1-dev | Continuous | 8× | 83.71 | 96.83 | 98.72 | 93.09 | 92.68 | 98.69 | 99.52 | 96.96 | 0.92 | 0.97 | 0.99 | 0.96 | |||