|
I am a final-year PhD student at the VLR Group in Huazhong University of Science and Technology under the supervision of Prof. Xiang Bai. My primary research interests lie in the field of Computer Vision, with a focus on visual generation, multimodal large language models, general image and video object perception algorithms. Specifically, I am currently exploring the exciting domains of multi-modal large models (MLLMs) and unified vision understanding and generation tasks. I also worked as a research intern at the ByteDance AI Lab, from 2021-2024.
I am currently on the job market. Please feel free to reach out if you are interested in my research. |

|
|
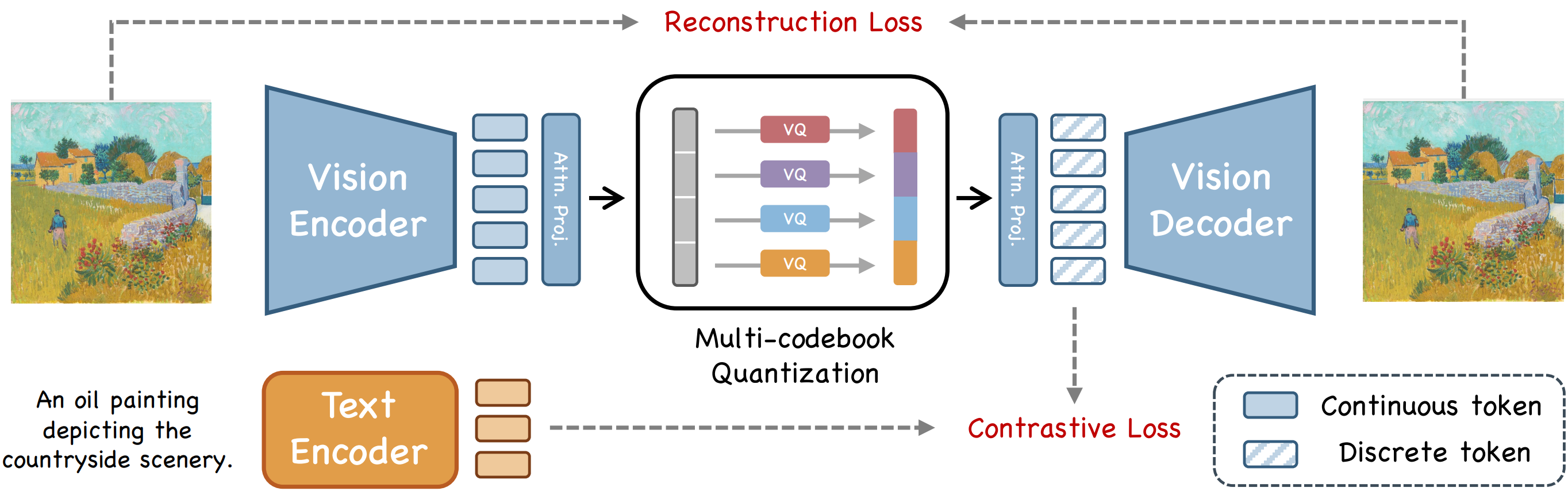
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, Xiaojuan Qi Arxiv, 2025 arXiv / code
|

|
Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, Xiang Bai Arxiv, 2024 arXiv / code
|

|
Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, Xiang Bai ECCV, 2024 arXiv / code
|
|
Junfeng Wu, Yi Jiang, QiHao Liu, Zehuan Yuan, Xiang Bai, Song Bai CVPR, 2024 (Highlight) arXiv / code / video
|
|
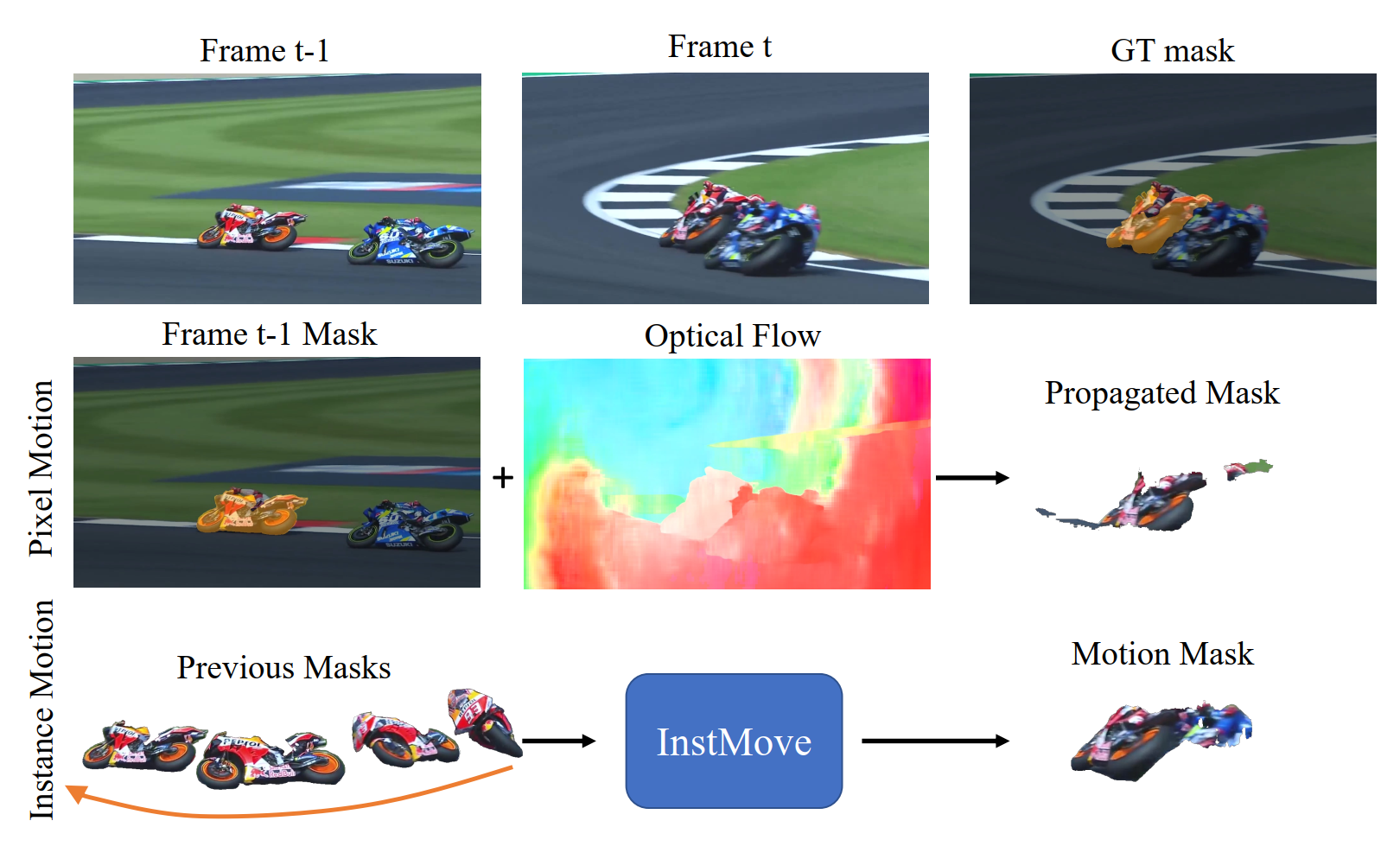
QiHao Liu, Junfeng Wu, Yi Jiang, Xiang Bai, Alan Yuille, Song Bai CVPR, 2023 arXiv / code
|
|
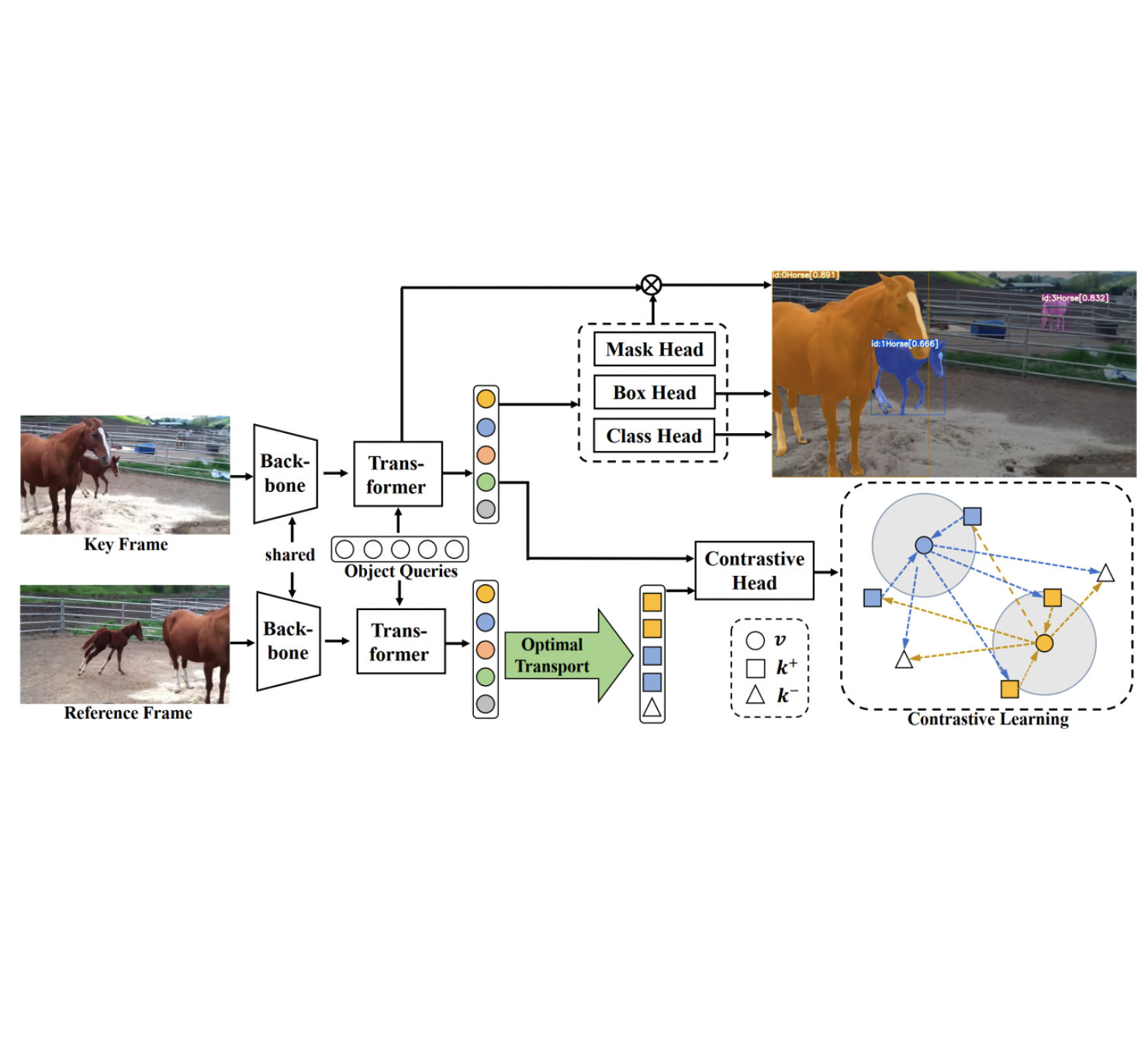
Junfeng Wu, QiHao Liu, Yi Jiang, Song Bai, Alan Yuille, Xiang Bai ECCV, 2022 (Oral Presentation) arXiv / code / video
|
|
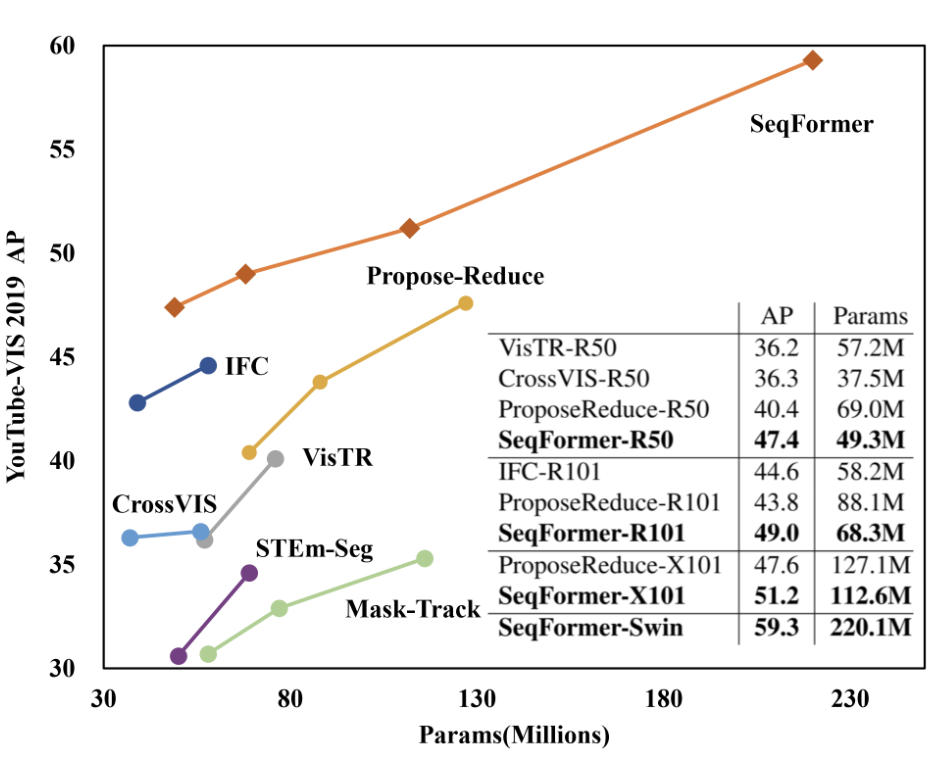
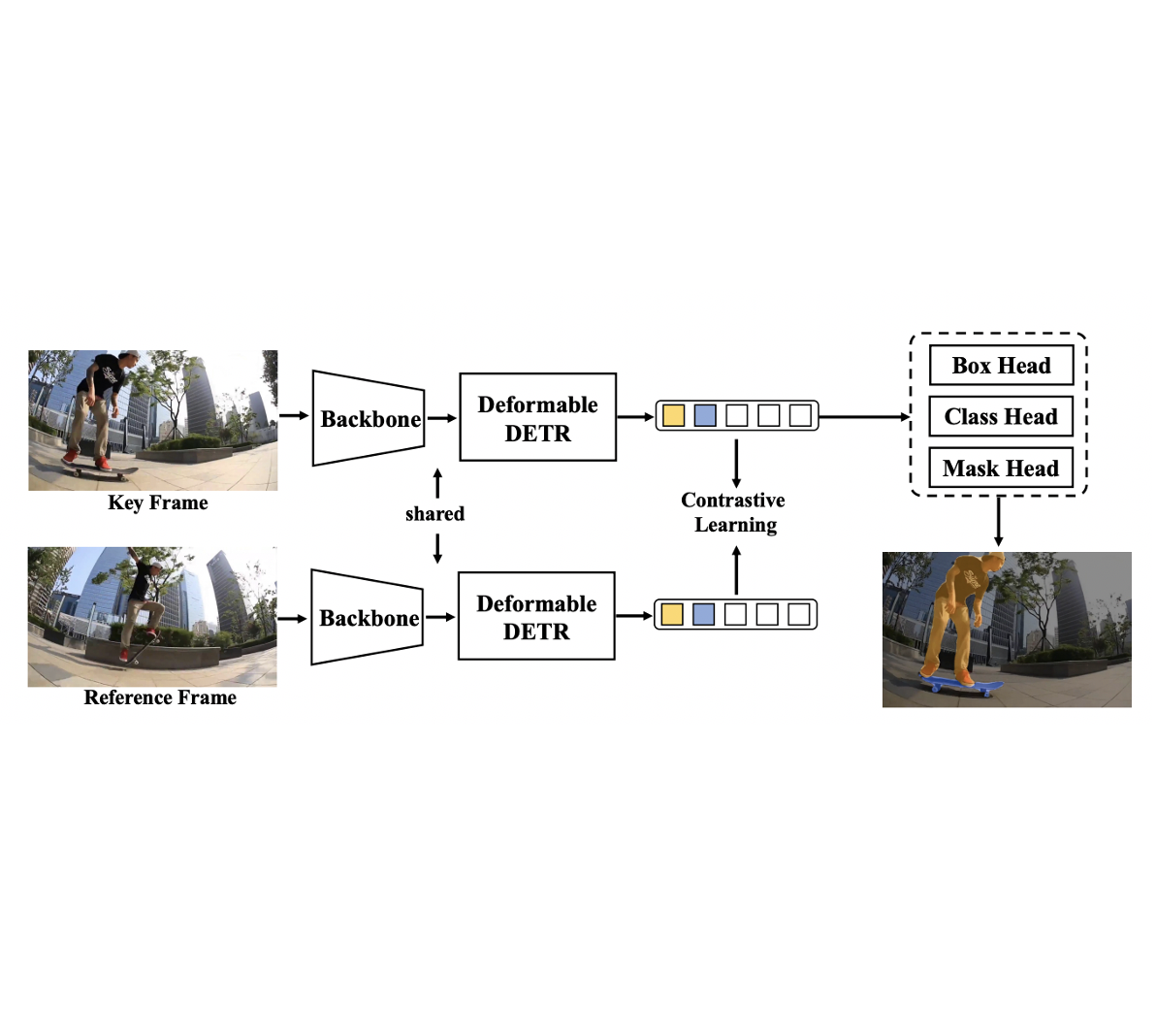
Junfeng Wu, Yi Jiang, Song Bai, Wenqing Zhang, Xiang Bai ECCV, 2022 (Oral Presentation) arXiv / code / |
|
Junfeng Wu, Xiang Bai, Yi Jiang, Qihao Liu, Zehuan Yuan, Song Bai CVPR, 2022 workshop code |
|
I actively serve as a reviewer for several leading conferences and journals in the field of computer vision and machine learning.
Conference Reviewer:
Journal Reviewer: |
|
Design and source code from Jon Barron's website. |